二分图判定算法
今天来讲一个经典图论算法:二分图判定。
二分图简介
先来看二分图的定义:
二分图的顶点集可分割为两个互不相交的子集,图中每条边依附的两个顶点都分属于这两个子集,且两个子集内的顶点不相邻。
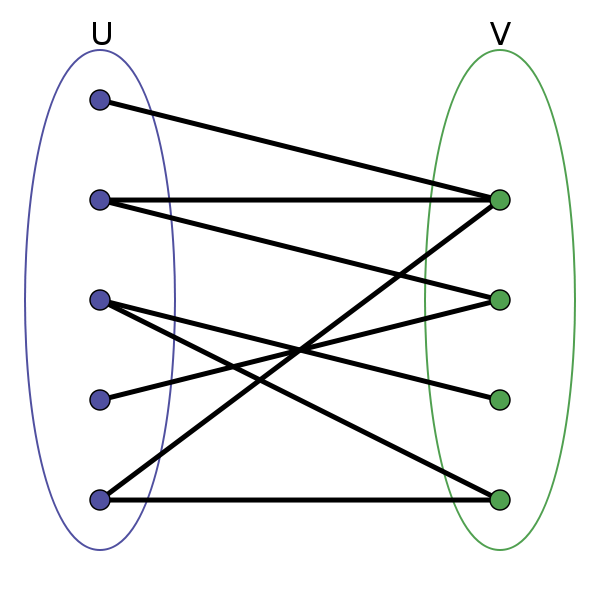
其实图论里面很多术语的定义都比较拗口,不容易理解。我们甭看这个死板的定义了,来玩个游戏吧:
给你一幅「图」,请你用两种颜色将图中的所有顶点着色,且使得任意一条边的两个端点的颜色都不相同,你能做到吗?
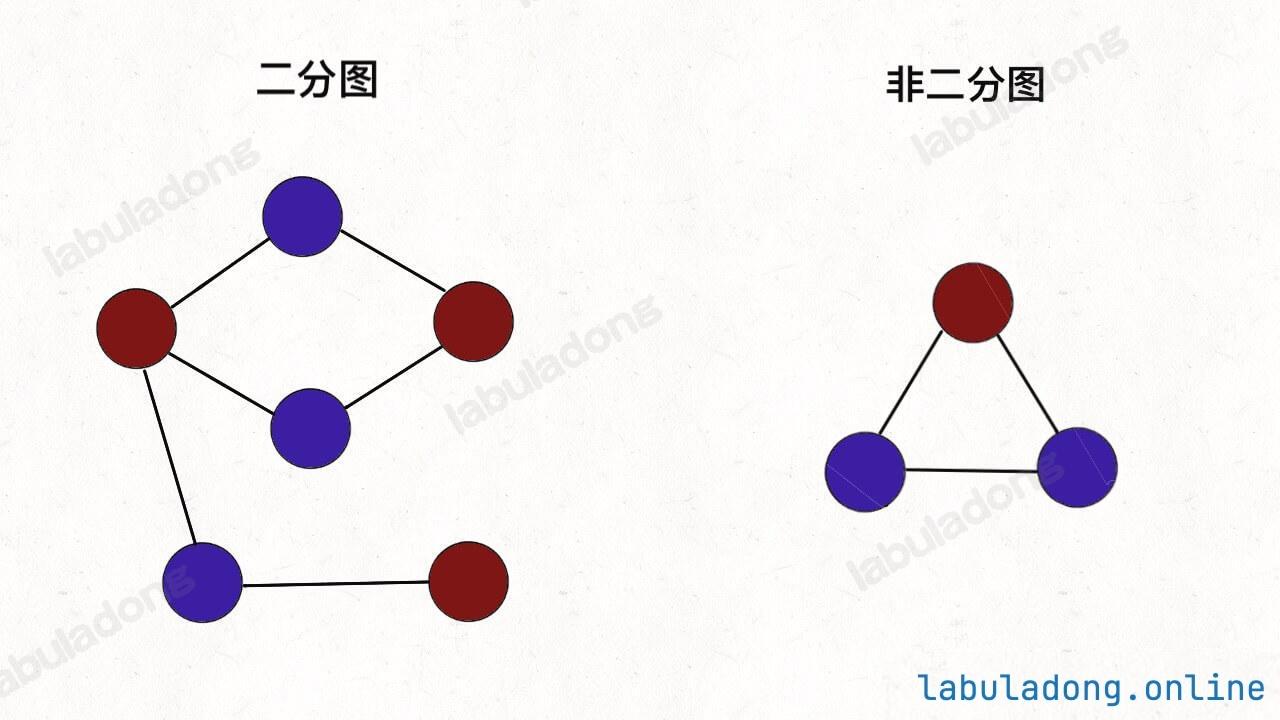
这就是图的「双色问题」,其实这个问题就等同于二分图的判定问题,如果你能够成功地将图染色,那么这幅图就是一幅二分图,反之则不是:
在具体讲解二分图判定算法之前,我们先来说说计算机大佬们闲着无聊解决双色问题的目的是什么。
首先,二分图作为一种特殊的图模型,会被很多高级图算法(比如最大流算法)用到,不过这些高级算法我们不是特别有必要去掌握,有兴趣的读者可以自行搜索。
从简单实用的角度来看,二分图结构在某些场景可以更高效地存储数据。
比如说我们需要一种数据结构来储存电影和演员之间的关系:某一部电影肯定是由多位演员出演的,且某一位演员可能会出演多部电影。你使用什么数据结构来存储这种关系呢?
既然是存储映射关系,最简单的不就是使用 哈希表 嘛,我们可以使用一个 HashMap<String, List<String>> 来存储电影到演员列表的映射,如果给一部电影的名字,就能快速得到出演该电影的演员。
但是如果给出一个演员的名字,我们想快速得到该演员演出的所有电影,怎么办呢?这就需要「反向索引」,对之前的哈希表进行一些操作,新建另一个哈希表,把演员作为键,把电影列表作为值。
显然,如果用哈希表存储,需要两个哈希表分别存储「每个演员到电影列表」的映射和「每部电影到演员列表」的映射。但如果用「图」结构存储,将电影和参演的演员连接,很自然地就成为了一幅二分图:
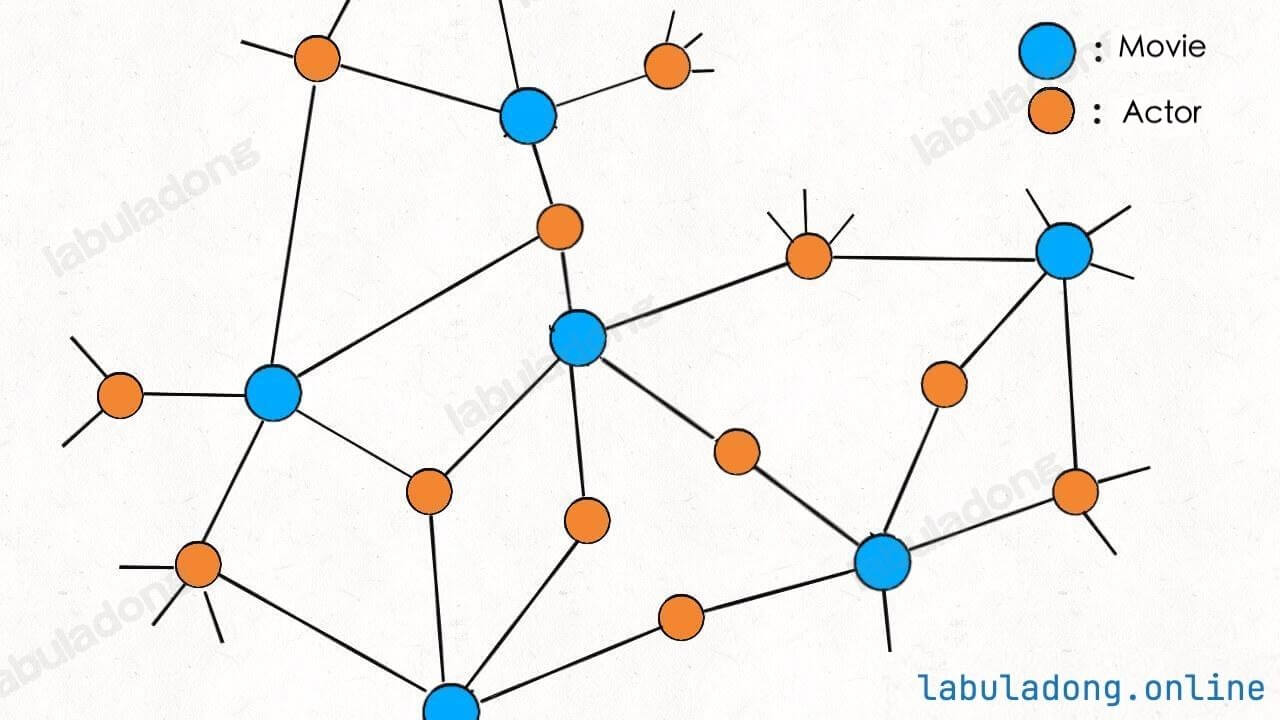
每个电影节点的相邻节点就是参演该电影的所有演员,每个演员的相邻节点就是该演员参演过的所有电影,对比哈希表的存储方式更方便直观,所需的存储空间更小。
其实生活中不少实体的关系都能自然地形成二分图结构,所以在某些场景下图结构也可以作为存储键值对的数据结构(符号表)。
好了,接下来进入正题,说说如何判定一幅图是否是二分图。
二分图判定思路
判定二分图的算法很简单,就是用代码解决「双色问题」。
说白了就是遍历一遍图,一边遍历一边染色,看看能不能用两种颜色给所有节点染色,且相邻节点的颜色都不相同。
既然说到遍历图,也不涉及最短路径之类的,当然是 DFS 算法和 BFS 皆可了,DFS 算法相对更常用些,所以我们先来看看如何用 DFS 算法判定双色图。
首先,基于 图结构的遍历 写出图的 DFS 遍历框架:
# 遍历图的所有节点
def traverse(graph, s, visited):
# base case
if s < 0 or s >= len(graph):
return
if visited[s]:
# 防止死循环
return
# 前序位置
visited[s] = True
print("visit", s)
for e in graph.neighbors(s):
traverse(graph, e.to, visited)
# 后序位置因为图中可能存在环,所以用 visited 数组防止走回头路。
这里可以看到我习惯把 return 语句都放在函数开头,因为一般 return 语句都是 base case,集中放在一起可以让算法结构更清晰。
其实,如果你愿意,也可以把 if 判断放到其它地方,比如图遍历框架可以稍微改改:
# 图遍历框架
visited = []
def traverse(graph: Graph, v: int):
# 前序遍历位置,标记节点 v 已访问
visited[v] = True
for neighbor in graph.neighbors(v):
if not visited[neighbor]:
# 只遍历没标记过的相邻节点
traverse(graph, neighbor)这种写法把对 visited 的判断放到递归调用之前,和之前的写法唯一的不同就是,你需要保证调用 traverse(v) 的时候,visited[v] == false。
为什么要特别说这种写法呢?因为我们判断二分图的算法会用到这种写法。
回顾一下二分图怎么判断,其实就是让 traverse 函数一边遍历节点,一边给节点染色,尝试让每对相邻节点的颜色都不一样。
所以,判定二分图的代码逻辑可以这样写:
# 图遍历框架
def traverse(graph, visited, v):
visited[v] = True
# 遍历节点 v 的所有相邻节点 neighbor
for neighbor in graph.neighbors(v):
if not visited[neighbor]:
# 相邻节点 neighbor 没有被访问过
# 那么应该给节点 neighbor 涂上和节点 v 不同的颜色
traverse(graph, visited, neighbor)
else:
# 相邻节点 neighbor 已经被访问过
# 那么应该比较节点 neighbor 和节点 v 的颜色
# 若相同,则此图不是二分图
pass如果你能看懂上面这段代码,就能写出二分图判定的具体代码了,接下来看两道具体的算法题来实操一下。
题目实践
力扣第 785 题「判断二分图」就是原题,题目给你输入一个 邻接表 表示一幅无向图,请你判断这幅图是否是二分图。
函数签名如下:
def isBipartite(graph: List[List[int]]) -> bool:比如题目给的例子,输入的邻接表 graph = [[1,2,3],[0,2],[0,1,3],[0,2]],也就是这样一幅图:
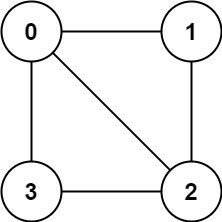
显然无法对节点着色使得每两个相邻节点的颜色都不相同,所以算法返回 false。
但如果输入 graph = [[1,3],[0,2],[1,3],[0,2]],也就是这样一幅图:
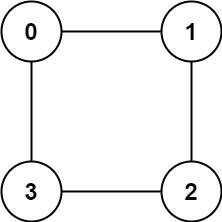
如果把节点 {0, 2} 涂一个颜色,节点 {1, 3} 涂另一个颜色,就可以解决「双色问题」,所以这是一幅二分图,算法返回 true。
结合之前的代码框架,我们可以额外使用一个 color 数组来记录每个节点的颜色,从而写出解法代码:
class Solution:
# 记录图是否符合二分图性质
# 记录图中节点的颜色,false 和 true 代表两种不同颜色
# 记录图中节点是否被访问过
def __init__(self):
self.ok = True
self.color = None
self.visited = None
# 主函数,输入邻接表,判断是否是二分图
def isBipartite(self, graph: List[List[int]]) -> bool:
n = len(graph)
self.color = [False] * n
self.visited = [False] * n
# 因为图不一定是联通的,可能存在多个子图
# 所以要把每个节点都作为起点进行一次遍历
# 如果发现任何一个子图不是二分图,整幅图都不算二分图
for v in range(n):
if not self.visited[v]:
self.traverse(graph, v)
return self.ok
# DFS 遍历框架
def traverse(self, graph: List[List[int]], v: int) -> None:
# 如果已经确定不是二分图了,就不用浪费时间再递归遍历了
if not self.ok:
return
self.visited[v] = True
for w in graph[v]:
if not self.visited[w]:
# 相邻节点 w 没有被访问过
# 那么应该给节点 w 涂上和节点 v 不同的颜色
self.color[w] = not self.color[v]
# 继续遍历 w
self.traverse(graph, w)
else:
# 相邻节点 w 已经被访问过
# 根据 v 和 w 的颜色判断是否是二分图
if self.color[w] == self.color[v]:
# 若相同,则此图不是二分图
self.ok = False你可以多次点击 这行代码,查看节点的染色过程。
算法可视化面板
接下来看一下 BFS 算法的逻辑:
from collections import deque
class Solution:
def __init__(self):
# 记录图是否符合二分图性质
self.ok = True
# 记录图中节点的颜色,False 和 True 代表两种不同颜色
self.color = []
# 记录图中节点是否被访问过
self.visited = []
def isBipartite(self, graph):
n = len(graph)
self.color = [False]*n
self.visited = [False]*n
for v in range(n):
if not self.visited[v]:
# 改为使用 BFS 函数
self.bfs(graph, v)
return self.ok
# 从 start 节点开始进行 BFS 遍历
def bfs(self, graph, start):
q = deque([start])
self.visited[start] = True
while q and self.ok:
v = q.popleft()
# 从节点 v 向所有相邻节点扩散
for w in graph[v]:
if not self.visited[w]:
# 相邻节点 w 没有被访问过
# 那么应该给节点 w 涂上和节点 v 不同的颜色
self.color[w] = not self.color[v]
# 标记 w 节点,并放入队列
self.visited[w] = True
q.append(w)
else:
# 相邻节点 w 已经被访问过
# 根据 v 和 w 的颜色判断是否是二分图
if self.color[w] == self.color[v]:
# 若相同,则此图不是二分图
self.ok = False
return核心逻辑和刚才实现的 traverse 函数(DFS 算法)完全一样,也是根据相邻节点 v 和 w 的颜色来进行判断的。关于 BFS 算法框架的探讨,详见前文 BFS 算法框架 和 Dijkstra 算法模板,这里就不展开了。
最后再来看看力扣第 886 题「可能的二分法」:
886. 可能的二分法 | 力扣
给定一组 n 人(编号为 1, 2, ..., n), 我们想把每个人分进任意大小的两组。每个人都可能不喜欢其他人,那么他们不应该属于同一组。
给定整数 n 和数组 dislikes ,其中 dislikes[i] = [ai, bi] ,表示不允许将编号为 ai 和 bi的人归入同一组。当可以用这种方法将所有人分进两组时,返回 true;否则返回 false。
示例 1:
输入:n = 4, dislikes = [[1,2],[1,3],[2,4]] 输出:true 解释:group1 [1,4], group2 [2,3]
示例 2:
输入:n = 3, dislikes = [[1,2],[1,3],[2,3]] 输出:false
示例 3:
输入:n = 5, dislikes = [[1,2],[2,3],[3,4],[4,5],[1,5]] 输出:false
提示:
1 <= n <= 20000 <= dislikes.length <= 104dislikes[i].length == 21 <= dislikes[i][j] <= nai < bidislikes中每一组都 不同
# 函数签名如下
def possibleBipartition(n: int, dislikes: List[List[int]]):其实这题考察的就是二分图的判定:
如果你把每个人看做图中的节点,相互讨厌的关系看做图中的边,那么 dislikes 数组就可以构成一幅图;
又因为题目说互相讨厌的人不能放在同一组里,相当于图中的所有相邻节点都要放进两个不同的组;
那就回到了「双色问题」,如果能够用两种颜色着色所有节点,且相邻节点颜色都不同,那么你按照颜色把这些节点分成两组不就行了嘛。
所以解法就出来了,我们把 dislikes 构造成一幅图,然后执行二分图的判定算法即可:
class Solution:
def __init__(self):
self.ok = True
self.color = None
self.visited = None
def possibleBipartition(self, n: int, dislikes: List[List[int]]) -> bool:
# 图节点编号从 1 开始
self.color = [False] * (n + 1)
self.visited = [False] * (n + 1)
# 转化成邻接表表示图结构
graph = self.buildGraph(n, dislikes)
for v in range(1, n + 1):
if not self.visited[v]:
self.traverse(graph, v)
return self.ok
# 建图函数
def buildGraph(self, n: int, dislikes: List[List[int]]) -> List[List[int]]:
# 图节点编号为 1...n
graph = [[] for _ in range(n + 1)]
for edge in dislikes:
v = edge[1]
w = edge[0]
# 「无向图」相当于「双向图」
# v -> w
graph[v].append(w)
# w -> v
graph[w].append(v)
return graph
# 和之前判定二分图的 traverse 函数完全相同
def traverse(self, graph: List[List[int]], v: int):
if not self.ok:
return
self.visited[v] = True
for w in graph[v]:
if not self.visited[w]:
self.color[w] = not self.color[v]
self.traverse(graph, w)
else:
if self.color[w] == self.color[v]:
self.ok = False算法可视化面板
至此,这道题也使用 DFS 算法解决了,如果你想用 BFS 算法,和之前写的解法是类似的,在扩散的时候,尝试对相邻元素颜色就行了,你可以自己尝试实现。
Hierholzer 算法寻找欧拉路径
在 欧拉图及一笔画游戏 中,我们通过经典的一笔画游戏学习了欧拉图的基本概念,探讨了欧拉路径/欧拉回路的判定条件。
关键就是看节点的度数,这里简单总结一下。如果你忘记了其中的原理,请先回去复习。
对于无向图:
- 如果所有节点的度数都是偶数,那么起点和终点是同一个节点,存在欧拉回路。我们可以以任意一个节点作为起点,遍历所有边后,一定可以回到起点。
- 如果存在两个奇数度节点,那么起点和终点分别是这两个节点,存在欧拉路径。我们可以任选一个奇数度节点作为起点,遍历所有边后,一定可以到达另一个奇数度节点。
对于有向图:
- 如果所有节点的入度和出度都相等,那么起点和终点是同一个节点,存在欧拉回路。我们可以以任意一个节点作为起点,遍历所有边后,一定可以回到起点。
- 如果存在两个节点入度和出度不相等,那么起点和终点分别是这两个节点,存在欧拉路径。我们可以任选一个入度和出度不相等的节点作为起点,遍历所有边后,一定可以到达另一个入度和出度不相等的节点。
接下来看看 Hierholzer 算法的代码实现,在 O(E)O(E) 时间复杂度内找到欧拉路径/欧拉回路。
Hierholzer 算法
Hierholzer 算法非常简单,本质就是 DFS 算法的逆后序遍历结果,分为以下几步:
1、根据每个节点的度数,确定欧拉路径/欧拉回路的起点。
2、从起点开始执行遍历所有边的 DFS 算法,记录后序遍历结果。
3、最后,将后序遍历结果反转,即可得到欧拉路径/欧拉回路。对于无向图,由于边没有方向的区别,所以即便不反转,结果也是对的。
我们可以直接复用 图结构的 DFS/BFS 遍历 中讲解的「遍历所有边的 DFS 算法」,在后序位置添加一行代码即可实现 Hierholzer 算法(伪码):
// 记录后序遍历结果
List<Integer> postOrder = new ArrayList<>();
// 从起点 s 开始遍历图的所有边
void traverseEdges(Graph graph, int s, boolean[][] visited) {
// base case
if (s < 0 || s >= graph.size()) {
return;
}
for (Edge e : graph.neighbors(s)) {
if (visited[s][e.to]) {
continue;
}
visited[s][e.to] = true;
traverseEdges(graph, e.to, visited);
}
// 后序位置,将当前节点添加到路径中
postOrder.add(s);
}
// 根据度数确定起点
int start = findStartNode(graph);
// 从起点开始执行 DFS 算法
traverseEdges(graph, start, visited);
// 将后序遍历结果反转,即可得到欧拉路径/回路
Collections.reverse(postOrder);不过 图结构的 DFS/BFS 遍历 中也讨论过,用二维 visited 数组来记录走过的边不是很好,因为需要创建一个二维数组,空间复杂度是 O(V2)O(V2),时间复杂度是 O(E+V2)O(E+V2),效率比较差。
其实还有其他的问题,比如对于求解欧拉路径的场景,是可以存在 多重边 的,也就是说两个相邻节点之间可以存在多条重复的边,而二维的 visited 数组不能处理这种情况。
所以我们需要更好的办法来处理已经遍历过的边避免重复遍历。
比方说可以给 Edge 类中添加一个 bool visited 字段来记录这条边是否被遍历过。这样不会引入新的空间复杂度,也能处理多重边的情况。
不过最常见的解法是:直接删掉已经遍历过的边,这样也能解决问题。
虽然删除边的操作会修改图结构,但是一般的算法题中,图结构本身就是我们自己构建的,所以修改图结构不是什么大问题。
基于这个思路,可以得到最终的 Hierholzer 算法代码(伪码):
// 记录后序遍历结果
List<Integer> postOrder = new ArrayList<>();
// 从起点 s 开始遍历图的所有边
void traverseEdges(Graph graph, int s) {
// base case
if (s < 0 || s >= graph.size()) {
return;
}
while (!graph.neighbors(s).isEmpty()) {
Edge e = graph.neighbors(s).get(0);
// 直接删除这条边
graph.removeEdge(s, e.to);
traverseEdges(graph, e.to);
}
// 后序位置,将当前节点添加到路径中
postOrder.add(s);
}
// 根据度数确定起点
int start = findStartNode(graph);
// 从起点开始执行 DFS 算法
traverseEdges(graph, start);
// 将后序遍历结果反转,即可得到欧拉路径/回路
Collections.reverse(postOrder);接下来给出一个比较完整的算法实现,其中的 Graph 接口来自 图结构的通用实现,给有向图、无向图提供了统一的 API,方便大家理解算法逻辑:
// Graph 类的通用实现参考
// https://labuladong.online/algo/data-structure-basic/graph-basic/
class HierholzerAlgorithm {
// 计算欧拉路径/回路,不存在则返回 null
public static List<Integer> findEulerianPath(Graph graph) {
// 1. 根据度数确定起点
int start = findStartNode(graph);
if (start == -1) {
// 不存在欧拉路径/回路
return null;
}
// 2. 从起点开始执行 DFS 算法,记录后序遍历结果
List<Integer> postOrder = new ArrayList<>();
traverse(graph, start, postOrder);
// 3. 反转后序遍历结果,即可得到欧拉路径/回路
Collections.reverse(postOrder);
return postOrder;
}
// 图结构的 DFS 遍历函数
private static void traverse(Graph graph, int u, List<Integer> postOrder) {
// base case
if (u < 0 || u >= graph.size()) {
return;
}
while (!graph.neighbors(u).isEmpty()) {
Edge edge = graph.neighbors(u).get(0);
int v = edge.to;
// 直接删掉边,避免重复遍历
graph.removeEdge(u, v);
traverse(graph, v, postOrder);
}
// 后序位置,记录后序遍历结果
postOrder.add(u);
}
// 根据度数确定起点,如果不存在欧拉路径,返回 -1
// 有向图和无向图的代码实现不同
private static int findStartNode(Graph graph) {
// ...
}
}对于有向图和无向图中的 Hierholzer 算法,有两个地方不同:
1、删除边的逻辑不同。无向图本质上是双向图,所以删除边的时候需要删除两条边,而有向图只需要删除一条边。不过我们使用了统一的 Graph 接口,所以这个差异已经在 removeEdge 方法中处理了。
2、判断起点和终点的逻辑不同。所以我们需要对有向图和无向图分别实现 findStartNode 函数。
无向图的 findStartNode 函数实现如下:
// 无向图的 findStartNode 函数实现
private static int findStartNode(Graph graph) {
int start = 0;
// 记录奇数度节点的数量
int oddDegreeCount = 0;
for (int i = 0; i < graph.size(); i++) {
if (graph.neighbors(i).size() % 2 == 1) {
oddDegreeCount++;
start = i;
}
}
// 如果奇数度节点的数量不是 0 或 2,则不存在欧拉路径
if (oddDegreeCount != 0 && oddDegreeCount != 2) {
return -1;
}
// 如果奇数度节点的数量是 0,则任意节点都可以作为起点,此时 start=0
// 如果奇数度节点的数量是 2,任意一个奇数度节点作为起点,此时 start 就是奇数度节点
return start;
}有向图的 findStartNode 函数实现如下:
// 有向图的 findStartNode 函数实现
private static int findStartNode(Graph graph) {
// 记录每个节点的入度和出度
int[] inDegree = new int[graph.size()];
int[] outDegree = new int[graph.size()];
for (int i = 0; i < graph.size(); i++) {
for (Edge edge : graph.neighbors(i)) {
inDegree[edge.to]++;
outDegree[i]++;
}
}
// 如果每个节点的入度出度都相同,则存在欧拉回路,任意节点都可以作为起点
boolean allSame = true;
for (int i = 0; i < graph.size(); i++) {
if (inDegree[i] != outDegree[i]) {
allSame = false;
break;
}
}
if (allSame) {
// 任意节点都可以作为起点,就让我们以 0 作为起点吧
return 0;
}
// 现在寻找是否存在节点 x 和 y 满足:
// inDegree[x] - outDegree[x] = 1 && inDegree[y] - outDegree[y] = -1
// 且其他节点的入度和出度都相等
// 如果存在,则 x 是起点,y 是终点
int x = -1, y = -1;
for (int i = 0; i < graph.size(); i++) {
int delta = inDegree[i] - outDegree[i];
if (delta == 0) {
continue;
}
if (delta != 1 && delta != -1) {
// 不存在欧拉路径
return -1;
}
if (delta == 1 && x == -1) {
x = i;
} else if (delta == -1 && y == -1) {
y = i;
} else {
// 不存在欧拉路径
return -1;
}
}
if (x != -1 && y != -1) {
// 存在欧拉路径,x 是起点
return x;
}
return -1;
}复杂度分析
Hierholzer 算法的时间复杂度主要来自 DFS 算法,为 O(E+V)O(E+V)。
空间复杂度主要来自图结构的存储,如果用邻接表存储图则为 O(E+V)O(E+V),如果用邻接矩阵存储图则为 O(V2)O(V2)。
正确性分析(可选)
Hierholzer 算法本质就是 DFS 算法,所以很容易写对。
但为什么对 DFS 的后序遍历结果进行反转(逆后序遍历),就可以得到欧拉路径/回路呢?逆后序遍历结果和前序遍历结果是什么关系,直接用前序遍历结果行不行?
这个逆后序遍历的原理比较精妙,需要对递归遍历的顺序有较深的认识,所以这部分内容是可选的,对于大部分读者来说,记住结论会写算法计算欧拉路径就可以了。
下面来分享一下我的理解,帮助大家尽可能直观地理解。我会结合可视化面板,从递归树的角度来直观地展示。
首先,欧拉图及一笔画游戏 中已经证明了解法的存在性:
我们可以通过节点的度数确定起点和终点,从起点出发必然存在一条路径可以到达终点,且恰好经过所有边一次。
现在我将证明,从起点开始进行 DFS 算法遍历图中的所有边,然后对后序遍历结果进行反转,得到的就是欧拉路径。
请想象从起点开始 DFS 遍历图结构所产生的递归树,欧拉路径既然是「一笔画」,理论上它的递归树应该就是一条类似单链表的形态,但实际上它可能有两种形态:
1、只有一条从根节点到叶子节点的路径,类似一条单链表。此时从根节点到叶子节点的递归路径就是欧拉路径。
2、有两条从根节点到叶子节点的路径。此时两个叶子节点之间的路径就是欧拉路径。
比方下面这幅无向图:
其中度数为奇数的节点为 0 和 3,所以起点要么选择 0,要么选择 3。请你想象一下 DFS 算法遍历的过程:
如果以节点 3 为起点,那么算法会直接遍历完右侧的所有节点 0,1,2,最后回退到起点 3,完成遍历。
这个过程的递归树就是由一条从根节点到叶子节点的树枝构成,类似一条单链表,下面的可视化面板展示了这一点:
算法可视化面板
请注意递归树,从递归树的根节点到叶子节点的递归路径就是欧拉路径 3->0->1->2->0,逆后序遍历结果确实和前序遍历结果相同。
如果你以节点 0 为起点,那么算法会先递归遍历左侧的节点(只有一个节点 3),然后回退到 0,去遍历右侧的节点(1 和 2),最后回到起点 0,完成遍历。
这个过程的递归树就是由两条从根节点到叶子节点的树枝构成,下面的可视化面板展示了这一点:
算法可视化面板
这种情况下的欧拉路径是 0->2->1->0->3,请注意递归树,可以发现以下的特点:
1、欧拉路径其实是从递归树的一个叶子节点(0)为起点,另一个叶子节点(3)为终点。
2、上面单链表形态的二叉树左旋一位,即可得到当前的递归树。
显然,这种情况下前序遍历结果不再能得到正确答案,而逆后序遍历结果依然是欧拉路径。
以上分析应该可以让你直观地理解逆后序遍历结果就是欧拉路径的原因了。
其实,从递归树的角度可以更深刻地理解欧拉路径,而且由于递归树形态比较简单,你会看到有些 Hierholzer 算法的实现是直接把递归算法改为基于栈的迭代算法。不过我还是建议用递归 DFS 算法,因为理解记忆的成本最低。
完成一笔画游戏
在 欧拉图及一笔画游戏 中展示了本站配套的一笔画游戏,现在你可以尝试用 Hierholzer 算法来辅助求解这个游戏了。
一笔画游戏
参考解法代码如下:
function solveOneStroke(graph) {
// 根据度数确定起点(题目保证必然存在欧拉路径)
let start = 0;
for (let node in graph) {
if (graph[node].length % 2 === 1) {
start = node;
break;
}
}
// 从起点开始执行 DFS 算法,记录后序遍历结果
let postOrder = [];
traverse(graph, start, postOrder);
// 反转后序遍历结果,即可得到欧拉路径
console.log(postOrder.reverse());
}
function traverse(graph, s, postOrder) {
while (graph[s].length > 0) {
// 无向图,删除两条边
let neighbor = graph[s].pop();
graph[neighbor].splice(graph[neighbor].indexOf(s), 1);
traverse(graph, neighbor, postOrder);
}
// 后序位置记录节点
postOrder.push(s);
}这段代码可以打印出欧拉路径,辅助你完成一笔画游戏。
到这里,Hierholzer 算法就讲完了,下一章我们来看一些实际的算法题目。
【练习】欧拉路径经典习题
欧拉路径相关的算法在力扣上都是 Hard 级别的题目,其难点主要在于如何把题目转化为求解欧拉路径的场景。
下面我们来看一些经典且有趣的题目。
332. 重新安排行程
332. 重新安排行程 | 力扣 | LeetCode | 🔴
给你一份航线列表 tickets ,其中 tickets[i] = [fromi, toi] 表示飞机出发和降落的机场地点。请你对该行程进行重新规划排序。
所有这些机票都属于一个从 JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 开始。如果存在多种有效的行程,请你按字典排序返回最小的行程组合。
- 例如,行程
["JFK", "LGA"]与["JFK", "LGB"]相比就更小,排序更靠前。
假定所有机票至少存在一种合理的行程。且所有的机票 必须都用一次 且 只能用一次。
示例 1:

输入:tickets = [["MUC","LHR"],["JFK","MUC"],["SFO","SJC"],["LHR","SFO"]] 输出:["JFK","MUC","LHR","SFO","SJC"]
示例 2:

输入:tickets = [["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]] 输出:["JFK","ATL","JFK","SFO","ATL","SFO"] 解释:另一种有效的行程是 ["JFK","SFO","ATL","JFK","ATL","SFO"] ,但是它字典排序更大更靠后。
提示:
1 <= tickets.length <= 300tickets[i].length == 2fromi.length == 3toi.length == 3fromi和toi由大写英文字母组成fromi != toi
这道题可以按照 回溯算法框架 写一个回溯算法暴力穷举所有路径,找到符合条件的行程。参考代码如下:
class Solution:
# 邻接表形式的图,key 是机场名字,value 是从该机场出发能够到达的机场列表
def __init__(self):
self.graph = {}
# 和 graph 对应,记录每张机票是否被使用过
# 比如 graph["JFK"][2] = true 说明从机场 JFK 出发的第 3 张机票已经用过了
self.used = {}
self.tickets = None
# 回溯算法使用的数据结构
self.track = []
# 回溯算法记录结果
self.res = None
def findItinerary(self, tickets: list[list[str]]) -> list[str]:
self.tickets = tickets
# 1. 用机场的名字构建邻接表
for ticket in tickets:
from_airport = ticket[0]
to_airport = ticket[1]
if from_airport not in self.graph:
self.graph[from_airport] = []
self.graph[from_airport].append(to_airport)
# 2. 对邻接表的每一行进行排序,保证字典序最小
for lst in self.graph.values():
lst.sort()
# 3. 初始化 used 结构,初始值都为 false
for key in self.graph:
size = len(self.graph[key])
self.used[key] = [False] * size
# 4. 从起点 "JFK" 开始启动 DFS 算法递归遍历
self.track.append("JFK")
self.backtrack("JFK")
return self.res
def backtrack(self, airport: str):
if self.res is not None:
# 已经找到答案了,不用再计算了
return
if len(self.track) == len(self.tickets) + 1:
# track 里面包含了所有的机票,即得到了一个合法的结果
# 注意 tickets.size() 要加一,因为 track 里面额外包含了起点 "JFK"
self.res = list(self.track)
return
if airport not in self.graph:
# 没有从 s 出发的边
return
# 遍历当前机场所有能够到达的机场
nextAirports = self.graph[airport]
for nextIndex in range(len(nextAirports)):
nextAirport = nextAirports[nextIndex]
if self.used[airport][nextIndex]:
# 如果这张机票被使用过,跳过
continue
# 做选择
self.used[airport][nextIndex] = True
self.track.append(nextAirport)
# 递归
self.backtrack(nextAirport)
# 撤销选择
self.used[airport][nextIndex] = False
self.track.pop()不过后来力扣似乎增加了一些测试用例,导致回溯算法超时了。
所以,这道题应该是想考察寻找 欧拉路径。Hierholzer 算法寻找欧拉路径 详细讲解了 Hierholzer 算法的原理和代码,这里直接套用即可。
需要注意的是,题目已经保证必然存在以 “JFK” 为起点的欧拉路径,所以不需要分析节点的度数寻找欧拉路径的起点;另外,题目要求返回字典序最小的行程,所以需要对邻接表中的每一个列表进行排序,确保 DFS 算法先遍历字典序最小的节点,最终得到的欧拉路径就是字典序最小的。
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
# 构建邻接表
from collections import defaultdict
graph = defaultdict(list)
for ticket in tickets:
graph[ticket[0]].append(ticket[1])
# 对每个出发点的目的地进行排序,确保字典序
for from_city in graph:
graph[from_city].sort()
# Hierholzer 算法寻找以 JFK 为起点的欧拉路径
# 计算以 JFK 为起点的后序遍历结果
postOrder = []
self.traverse(graph, "JFK", postOrder)
# 反转后序遍历结果,得到欧拉路径
postOrder.reverse()
return postOrder
def traverse(self, graph: dict, node: str, postOrder: List[str]) -> None:
if node not in graph:
postOrder.append(node)
return
# 复制节点列表,避免在遍历过程中修改原列表
while graph[node]:
v = graph[node][0]
graph[node].pop(0)
self.traverse(graph, v, postOrder)
# 获取后序遍历结果
postOrder.append(node)2097. 合法重新排列数对
2097. 合法重新排列数对 | 力扣 | LeetCode | 🔴
给你一个下标从 0 开始的二维整数数组 pairs ,其中 pairs[i] = [starti, endi] 。如果 pairs 的一个重新排列,满足对每一个下标 i ( 1 <= i < pairs.length )都有 endi-1 == starti ,那么我们就认为这个重新排列是 pairs 的一个 合法重新排列 。
请你返回 任意一个 pairs 的合法重新排列。
注意:数据保证至少存在一个 pairs 的合法重新排列。
示例 1:
输入:pairs = [[5,1],[4,5],[11,9],[9,4]] 输出:[[11,9],[9,4],[4,5],[5,1]] 解释: 输出的是一个合法重新排列,因为每一个 endi-1 都等于 starti 。 end0 = 9 == 9 = start1 end1 = 4 == 4 = start2 end2 = 5 == 5 = start3
示例 2:
输入:pairs = [[1,3],[3,2],[2,1]] 输出:[[1,3],[3,2],[2,1]] 解释: 输出的是一个合法重新排列,因为每一个 endi-1 都等于 starti 。 end0 = 3 == 3 = start1 end1 = 2 == 2 = start2 重新排列后的数组 [[2,1],[1,3],[3,2]] 和 [[3,2],[2,1],[1,3]] 都是合法的。
示例 3:
输入:pairs = [[1,2],[1,3],[2,1]] 输出:[[1,2],[2,1],[1,3]] 解释: 输出的是一个合法重新排列,因为每一个 endi-1 都等于 starti 。 end0 = 2 == 2 = start1 end1 = 1 == 1 = start2
提示:
1 <= pairs.length <= 105pairs[i].length == 20 <= starti, endi <= 109starti != endipairs中不存在一模一样的数对。- 至少 存在 一个合法的
pairs重新排列。
这道题属于 Hierholzer 算法寻找欧拉路径 的模板题,直接套用模板即可。
pairs 数组中每个数对 [a, b] 表示一条 a->b 的有向边,题目其实是要我们在图中找到一条欧拉路径。
最后找到的这条欧拉路径中,每两个相邻的节点组成一个数对,就得到了题目想要的答案。
比如说欧拉路径为 0->1->2->3->1,那么题目想要的答案就是 [[0, 1], [1, 2], [2, 3], [3, 1]]。
具体请看解法代码的注释。
class Solution:
def validArrangement(self, pairs: List[List[int]]) -> List[List[int]]:
# 建图
from collections import defaultdict, deque
graph = defaultdict(list)
inDegree = defaultdict(int)
outDegree = defaultdict(int)
for pair in pairs:
from_, to = pair[0], pair[1]
graph[from_].append(to)
inDegree[to] += 1
outDegree[from_] += 1
# 找起点,题目说了必然存在一个起点
# 所以我们只需要寻找出度比入度大 1 的节点作为起点
# 如果没有出度比入度大 1 的节点,说明存在欧拉回路
# 任选一个节点作为起点就可以
start = pairs[0][0]
for node in graph.keys():
if outDegree.get(node, 0) - inDegree.get(node, 0) == 1:
start = node
break
# 从起点开始 DFS 遍历,计算后序遍历结果
postOrder = []
def traverse(graph, node, postOrder):
while graph[node]:
# 弹出最后一个元素,因为数组删除最后元素的复杂度是 O(1)
to = graph[node].pop()
traverse(graph, to, postOrder)
postOrder.append(node)
traverse(graph, start, postOrder)
# 反转后序遍历结果,得到欧拉路径
postOrder.reverse()
# 将后序遍历结果转换为结果数组
result = []
for i in range(len(pairs)):
result.append([postOrder[i], postOrder[i + 1]])
return result753. 破解保险箱
753. 破解保险箱 | 力扣 | LeetCode | 🔴
有一个需要密码才能打开的保险箱。密码是 n 位数, 密码的每一位都是范围 [0, k - 1] 中的一个数字。
保险箱有一种特殊的密码校验方法,你可以随意输入密码序列,保险箱会自动记住 最后 n 位输入 ,如果匹配,则能够打开保险箱。
- 例如,正确的密码是
"345",并且你输入的是"012345":- 输入
0之后,最后3位输入是"0",不正确。 - 输入
1之后,最后3位输入是"01",不正确。 - 输入
2之后,最后3位输入是"012",不正确。 - 输入
3之后,最后3位输入是"123",不正确。 - 输入
4之后,最后3位输入是"234",不正确。 - 输入
5之后,最后3位输入是"345",正确,打开保险箱。
- 输入
在只知道密码位数 n 和范围边界 k 的前提下,请你找出并返回确保在输入的 某个时刻 能够打开保险箱的任一 最短 密码序列 。
示例 1:
输入:n = 1, k = 2 输出:"10" 解释:密码只有 1 位,所以输入每一位就可以。"01" 也能够确保打开保险箱。
示例 2:
输入:n = 2, k = 2 输出:"01100" 解释:对于每种可能的密码: - "00" 从第 4 位开始输入。 - "01" 从第 1 位开始输入。 - "10" 从第 3 位开始输入。 - "11" 从第 2 位开始输入。 因此 "01100" 可以确保打开保险箱。"01100"、"10011" 和 "11001" 也可以确保打开保险箱。
提示:
1 <= n <= 41 <= k <= 101 <= kn <= 4096
首先要确保你理解了题目,比如说 n = 2, k = 3 的例子,所有可能的密码有 32=932=9 种(全排列),分别是 00, 01, 02, 10, 11, 12, 20, 21, 22。
那么如果我把这 9 个排列直接链接成一个字符串,就得到了 000102101112202122,长度为 2×9=182×9=18。
如果把这个字符串输入给密码箱,必然能够打开密码箱,因为其中已经包含了所有可能的密码。
不过题目要求我们找到一个最短的密码破解序列,而这个字符串并不是最短的。比方说 0221120100 应该是最优解,你看这个字符串中包含了 9 种密码,且长度仅为 10,小于 18。
所以这个题目不是一个简单的排列组合问题,需要更巧妙的解法。
这类「包含所有全排列的最短序列」是经典的欧拉路径问题,没有了解过这类问题的话,几乎没办法想到如何把这个题抽象成寻找欧拉回路的场景。所以我直接说解法,大家把这个破解密码的场景记下来即可。
让我们考虑 n=3, k=2 的例子,所有可能的密码有 23=823=8 种,分别是:
000 001
010 011
100 101
110 111我们现在想计算一个最短的字符串 t,使得 t 中包含上面所有 8 个密码,且 t 的长度尽可能小。
首先,列出 n=2, k=2 的 22=422=4 种全排列:
00 01
10 11把这 4 个排列视为一幅有向图中的 4 个节点:
给这幅图添加若干有向边,就可以推导出 n=3, k=2 的最短密码序列了。
我们可以认为每个节点都有 k 条出边指向其他节点(也可以指向自己),每一条边都代表着一位新的密码。
比方说节点 00 有 2 条出边,分别代表着 0, 1 两位数字,也就是说从 00 出发,可以生成 000, 001 两个新密码。
但是我们的图结构中每个节点都只有两位,并不存在 000, 001 这两个节点,应该如何添加 00->000, 00->001 这两条边呢?
很简单,我们仅看后缀,也就是说把 00 节点连接到 00, 01 这两个节点,即添加 00->00, 00->01 这两条边。
其他节点同理,01 节点连接到 10, 11 这两个节点,10 节点连接到 00, 01 这两个节点,11 节点连接到 10, 11 这两个节点。
到这里,有向图图结构就建好了:
对于这幅有向图,每个节点都有 k=2 条出边,同时也有 k=2 条入边,所以这是一幅欧拉图,存在 欧拉回路,能够从任意一个节点出发,遍历所有边恰好一次,最终回到起点。
而这条欧拉回路,就可以推导出我们想要的密码破解序列。
比方说一个正确的最短序列是 t = "0011101000",体现在图中就是以 00 作为起点的欧拉回路,推导过程如下。
首先,我们以 00 节点作为欧拉路径的起点,初始化 t = "00"。
节点 00 经过边 1 到达节点 01,此时 t = "001"。
节点 01 经过边 1 到达节点 11,此时 t = "0011"。
节点 11 经过边 1 到达节点 11,此时 t = "00111"。
节点 11 经过边 0 到达节点 10,此时 t = "001110"。
节点 10 经过边 1 到达节点 01,此时 t = "0011101"。
节点 01 经过边 0 到达节点 10,此时 t = "00111010"。
节点 10 经过边 0 到达节点 00,此时 t = "001110100"。
节点 00 经过边 0 到达节点 00,此时 t = "0011101000"。
这就是一条欧拉回路,我们从 00 节点出发,遍历了图中的所有边,最终回到了 00 节点,同时得到了密码破解序列 t = "0011101000"。
上述过程就是这道题的核心思路,直接翻译成代码,应该就可以完成这道题。
首先用回溯算法计算出 kn−1k**n−1 个全排列作为节点构建图结构,然后任选一个节点作为起点,执行 Hierholzer 算法 计算欧拉回路,最后拼接出最终答案。
题目给的取值范围 kn<=4096k**n<=4096,并不算大,所以回溯算法计算全排列也不会很耗时。
但其实有更简单的办法,不需要计算全排列,甚至都不需要用邻接表/邻接矩阵构建图结构,就能完成这道题。
注意观察可以发现以下规律:
1、除了起点,我们并没有用到其他节点的值,主要是通过边上的值拼接出最终答案的。
2、每个节点必然有 k 条出边,边上的值是 0, 1, 2, ..., k-1。
3、题目说 1<=k<=101<=k<=10,所以可以通过当前节点的值和边的值推导出下一个节点,即 (当前节点值 * 10 + 边值) % 10^{n-1}。
比方说 10 节点经过边 1 到达 01 节点,即 (10 * 10 + 1) % 10^2 = 1。
综上,我们不需要使用邻接表/邻接矩阵存储图结构,具体看代码吧。
class Solution {
// 记录哪些边被访问过,其中的元素类似 "0->10", "11->1" 这种形式
HashSet<String> visited = new HashSet<>();
// 记录后序遍历结果
List<Integer> postOrder = new ArrayList<>();
// 计算获取个位数的求余基数
int base;
public String crackSafe(int n, int k) {
if (n == 1) {
// 如果 n=1,则直接返回 0,1,2,...,k-1 的拼接
StringBuilder sb = new StringBuilder();
for (int i = 0; i < k; i++) {
sb.append(i);
}
return sb.toString();
}
base = (int) Math.pow(10, n - 1);
// 图中必然存在欧拉回路
// 所以可以从任意节点开始 Hierholzer 算法
traverse(0, k);
// 把后序遍历结果反转,即可得到欧拉回路
Collections.reverse(postOrder);
// 欧拉回路经过的边可以拼接出答案
StringBuilder sb = new StringBuilder();
// 开头是起点的值,即长度为 n-1 的 0
sb.append("0".repeat(n - 1));
// 从起点开始拼接每条边的值
for (int i = 0; i < postOrder.size() - 1; i++) {
int nextNode = postOrder.get(i + 1);
// nextNode 的个位数的值就是边的值
sb.append(nextNode % 10);
}
return sb.toString();
}
void traverse(int node, int k) {
for (int i = 0; i < k; i++) {
int nextNode = (node * 10 + i) % base;
// 由于未使用邻接表,不能直接删边
// 所以借助 visited 记录已访问边
String edge = node + "->" + nextNode;
if (!visited.contains(edge)) {
visited.add(edge);
traverse(nextNode, k);
}
}
// 记录后序遍历结果
postOrder.add(node);
}
}


